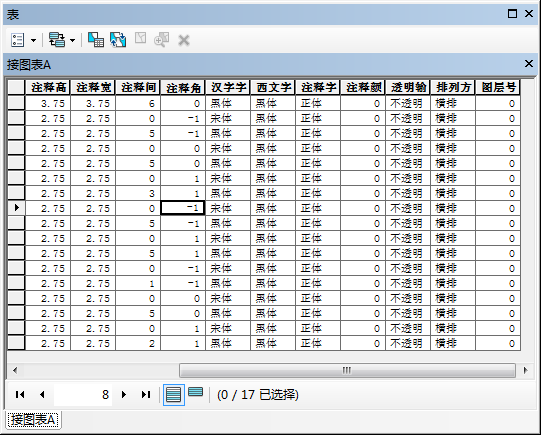
在使用Shape文件时,如果里面有中文属性信息时,经常会遇到属性信息变为乱码。尤其是ArcGIS10.2.1之后,Esri改变了软件的默认字符编码规则,打开之前保存的Shapefile文件,总会不时遇到中文字符出现乱码现象。对此问题,网上好多建议是修改系统注册表或全局的字符编码设置,这样做固然有效,但这样会引起打开其它种类字符编码数据显示乱码的的问题;另外当我们拿到一个显示乱码的Shape数据,我们也很难猜出它本身是什么字符集的数据,使得乱码问题成为一个极其困扰的问题。
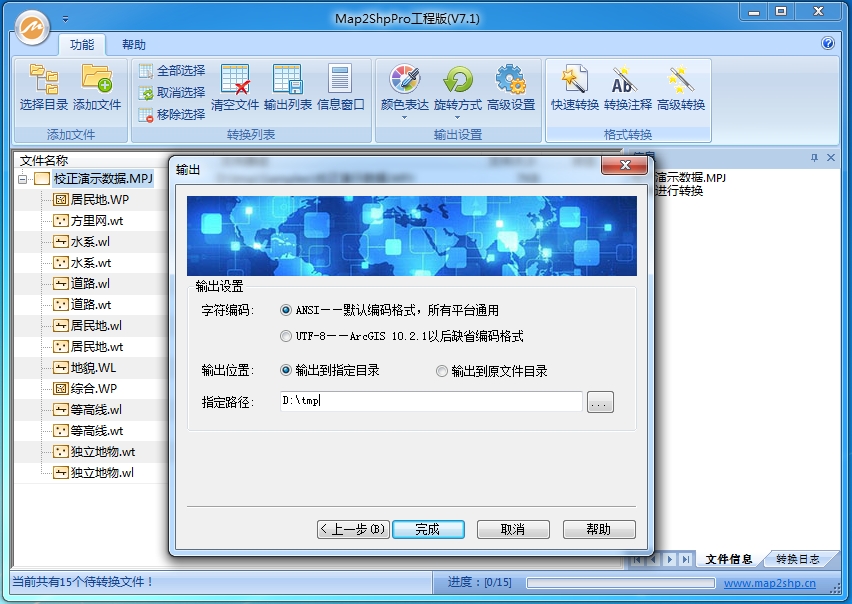
为此,Map2Shp软件提供了专门的解决方案。转换结果输出时,可以选择Shape文件的字符编码(如图)。其中,ArcMap10.2及以前版本,中文字符默认采用ANSI编码,与操作系统默认编码格式一致,多为GBK编码方式,不会出现中文乱码,具有较广的通用性。ArcGIS10.2.1及之后版本,中文字符默认采用UTF-8编码,ArcGIS会先读取DBF头文件LDID中的编码,然后是cpg文件,最后是CodePage。Map2Shp输出UTF-8编码文件时,转换结果文件中增加一个.cpg文件,文件里面定义了dbf所使用的编码格式为UTF-8,ArcMap会读取.cpg文件来判断文件的编码,打开就不会有乱码。
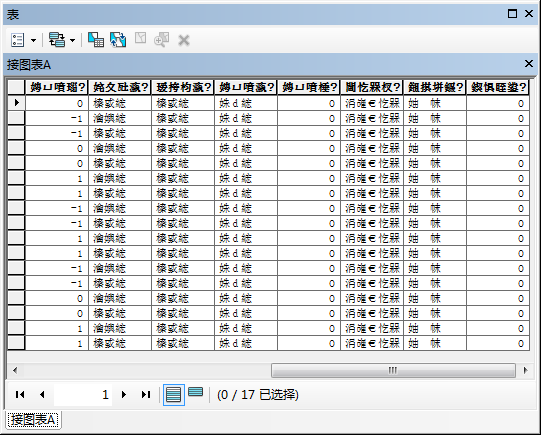
总体上来说,Shape文件中文出现乱码的根本原因是读取文件使用的编码类型和文件实际存储的编码类型不一致所致,Map2Shp提供的解决方案中确保了编码信息的一致性,无论选用何种编码方式,在ArcGIS不同版本下均能够正确识别,彻底解决了中文乱码问题。
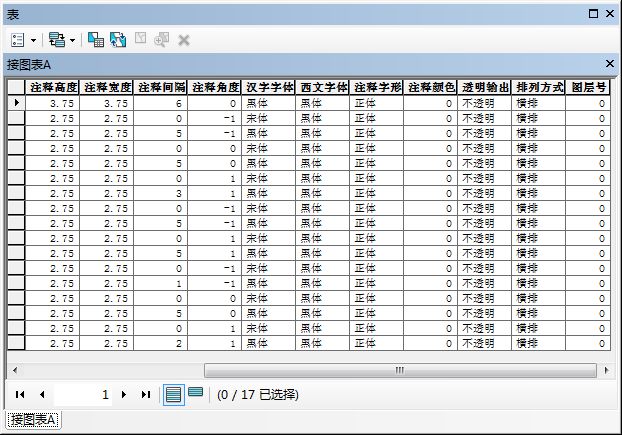
此外,由于shape文件自身限制,属性字段名称长度不能超过9个字节,而UTF-8 编码下单个汉字至少需要3个字节存储,因此UTF-8 编码下shape文件字段名称会被截断为最长3个汉字,而存在字段名称截断丢失现象。